반응형
블로그 너무 오랜만이다........
이직한다는 핑계로....
이직성공했다는 핑계로....
난 멈춰있었다....
(참고한 코드 : https://github.com/lovelynrose/chatgpt/blob/main/pdfchat.ipynb)
일단 코드를 간단히 소개하면
input : 아무 pdf (여기서는 sk의 지속가능 경영보고서)
SK-Inc_지속가능경영보고서_2023_KOR.pdf
14.71MB
output : gpt api를 사용해서 pdf 내용을 질문하면 답해주는 선생님
아마도 코드 부분에서는 api key 값만 바꾸면 다 잘되실거에요.
또한 install 하라는 거 install 하시면 무리 없이 도실 겁니다.
다만, 아직 pdf의 구조를 잘 이해 못하는 거 같습니다.
그리하여 다음엔 라바 파서를 사용해보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
!pip install openai langchain pypdf chromadb tiktoken
!conda search python
!python --version
!pip install openai
pip show openai
import openai
openai.api_key = '여기다 당신의 api key를 넣으세요'
system_template = """Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Begin!
----------------
Question: {question}
Helpful Answer:"""
print('what is going on?')
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template("{question}")
]
prompt = ChatPromptTemplate.from_messages(messages)
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("SK-Inc_지속가능경영보고서_2023_KOR.pdf")
data = loader.load()
len(data)
# For checking
# Create Document objects for each text chunk
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 200)
texts = text_splitter.split_documents(data)
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embedding=OpenAIEmbeddings(openai_api_key = openai.api_key)
vectorstore = Chroma.from_documents(documents=texts,embedding=embedding)
from langchain_openai import ChatOpenAI
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613",openai_api_key = openai.api_key)
question = "What are the languages considered"
'''docs = vectorstore.similarity_search(question)
len(docs)'''
from langchain.chains import RetrievalQA
prompt
def qa(question, answer_list):
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs = {"prompt": prompt})
result = qa_chain({"query": question})
answer_list.append(result)
print(result)
answer_list = []
now = qa('ESG 기반의 4대 핵심 영역 포트폴리오가 뭐야?', answer_list)
print(answer_list)
now = qa('등기이사의 보수총액은 얼마나되?', answer_list)
now = qa('SK의 사외이사 비율이 얼마나되?', answer_list)
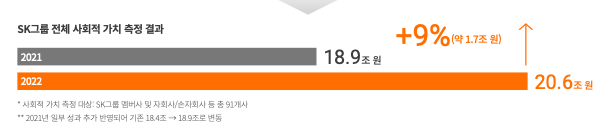
now = qa('SK는 전체 사회적 가치 측정 결과 전년 대비 몇 퍼센트나 증가했어?', answer_list)
|
cs |



이제 난!!! 다시!!!! 해낸다!!!!
2000억 부자가 되기 위해!!!!!!
댓글로 질문 주시면 성실히 답변드립니다.
Be positive
Be rich!
Live your life!!!
감사합니다.
반응형
'Programming' 카테고리의 다른 글
| 임베딩, RAG, Lang chain 나도 할 수 있다 #2 (0) | 2024.05.12 |
|---|---|
| 이중배열 얕은 깊은 복사_코테 복기_0815 (0) | 2023.08.15 |
| 강화학습_7_0814 (0) | 2023.08.15 |
| 강화학습_6_0810_DQN (0) | 2023.08.11 |
| 강화학습_5_0809 (0) | 2023.08.09 |



